Creating Plots in Jupyter Notebooks#
Overview
Questions:
How can I plot and annotate my data in Jupyter notebooks?
Objectives:
Repeat linear regression on the protein assay data to obtain best fit statistics.
Create a plot of the data with the best fit line.
Create a plot that includes confidence intervals.
Preparing to Plot#
In recent lessons, we have learned to use pandas to import csv data into a dataframe that is very easy to access and can be used for plotting our data. We have also learned to do linear regression analysis using scipy. In this lesson, we will create linear regression plots of our data using two different libraries, matplotlib.pyplot and seaborn. As we add more libraries to our repretoire, we are going to track them in a table.
Library |
Uses |
Abbreviation |
|---|---|---|
os |
file management in operating systems |
os |
numpy |
calculations |
np |
pandas |
data management |
pd |
scipy |
calculations and statistics |
sc or sp |
matplotlib.pyplot |
plotting data |
plt |
seaborn |
plotting data |
sns |
We will start by importing the data and linear regresson analysis from the previous lesson.
import os
import pandas as pd
protein_file = os.path.join('data', 'protein_assay.csv')
results_df = pd.read_csv(protein_file)
xdata = results_df['Protein Concentration (mg/mL)'] # Setting the x values
ydata = results_df['A595'] # setting the y values
from scipy import stats
slope, intercept, r_value, p_value, std_err = stats.linregress(xdata, ydata)
print("Slope = ", slope, "/mg/mL", sep = "")
print("Intercept = ", intercept)
print("R-squared = ", r_value**2)
print("P value = ", p_value)
print("Standard error = ", std_err)
Slope = 0.8454285714285716/mg/mL
Intercept = 0.12786666666666657
R-squared = 0.994690398528738
P value = 1.0590717448341336e-05
Standard error = 0.030884027089284245
Using Matplotlib.pyplot#
Matplotlib is a library that supports static, animated and interactive data visualization in Python (Matplotlib: Visualization with Python). Matplotlib is used alongside numpy to provide for MATLAB-style plotting. You can use matplotlib to create and fully annotate high resolution, publication quality plots that can be easily exported for inclusion in reports and manuscripts. It is possible to create many graph formats in matplotlib, including “picture within a picture graphs.” Think of the chart options that are available in your spreadsheet program. These are all available with matplotlib, plus many more.
We are going to use one subset of matplotlib’s functions called pyplot. This approach is similar to using the stats subset of the functions found in scipy. This library contains tools for plotting and annotating the data. Let’s start with a simple x-y scatter plot of the protein calibration curve data. First, we need to import the library, set the size of the figure and indicate the data for the plot.
import numpy as np
import matplotlib.pyplot as plt
plt.figure(figsize = (10,5)) # set the size of the figure
plt.scatter(xdata, ydata) # scatter plot of the data
<matplotlib.collections.PathCollection at 0x7f478ffb8110>
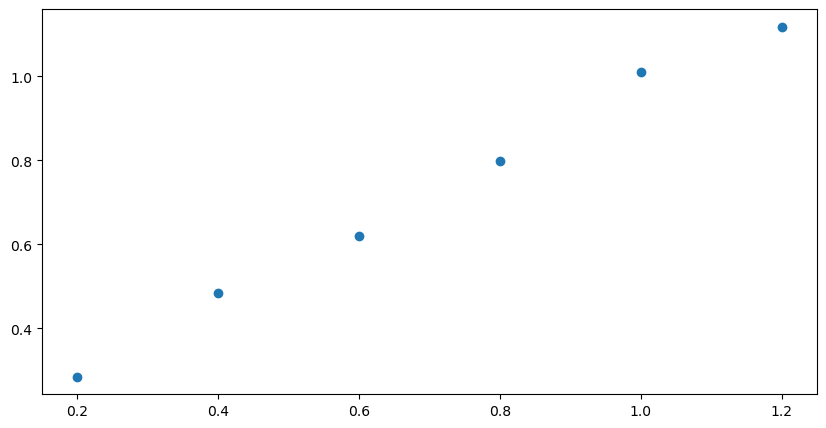
Next we add the best fit line using the slope and intercept that were generated by the stats.linregress function from scipy. The first two lines in the next cell are identical to the cell above (no need to import the libraries again). The third line introduces the best fit curve. You may notice a delay of a few seconds as the notebook generates the figure. The more complex the figure and the larger the dataset, the longer it takes for the plot to appear.
plt.figure(figsize = (10,6))
plt.scatter(xdata, ydata)
plt.plot(xdata, slope * xdata + intercept) # introduce the best-fit line
[<matplotlib.lines.Line2D at 0x7f478fc60a10>]
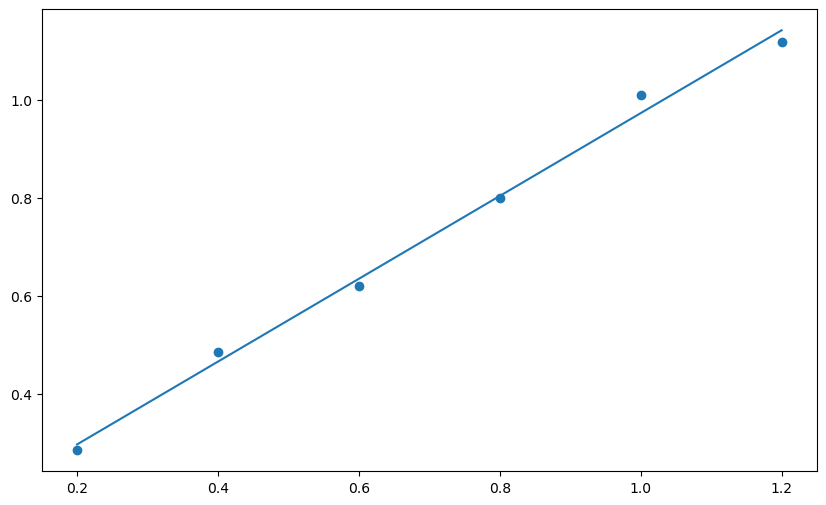
Next we will use functions for matplotlib.pyplot to add labels for each axis. It is possible to include subscripts and Greek letters in matplotlib figure labels using LaTeX. Here is a link to a helpful site about using markdown (used for the text cells in Jupyter notebook) and LaTeX in Jupyter notebooks by Khelifi Ahmed Aziz.
Greek letters using LaTeX: You can use an inline LaTeX equation to print Greek letters in matplotlib figures, using this format:
Start with a dollar sign: $
Type a backslash $\
Type the English version of the Greek letter, $\mu
End with a dollar sign \$\mu$
Examples: \\(\\alpha\\\) display as \(\alpha\); \\(\\mu\\\) displays as \(\mu\)
The command for printing the line equation includes F, which stands for formatted string literal. By using F it is possible to pull the values for slope and intercept that were generated with scipy.stats, by enclosing the variable names in braces, {}. It is also possible to set the precision by following the variable name with :.4f where 4 is the number of decimal places you want to appear and f represents the datatype, float.
plt.figure(figsize = (10,6))
plt.scatter(xdata, ydata)
plt.plot(xdata, slope * xdata + intercept)
plt.xlabel('Protein Concentration (mg/mL)') # x-axis label
plt.ylabel('$A_{595}$') # y-axis label in LaTeX _{595} makes 595 the subscripts
plt.annotate(F'y = {slope:.4f} * x + {intercept:.4f}', xy = (0.25, 1.0))
Text(0.25, 1.0, 'y = 0.8454 * x + 0.1279')
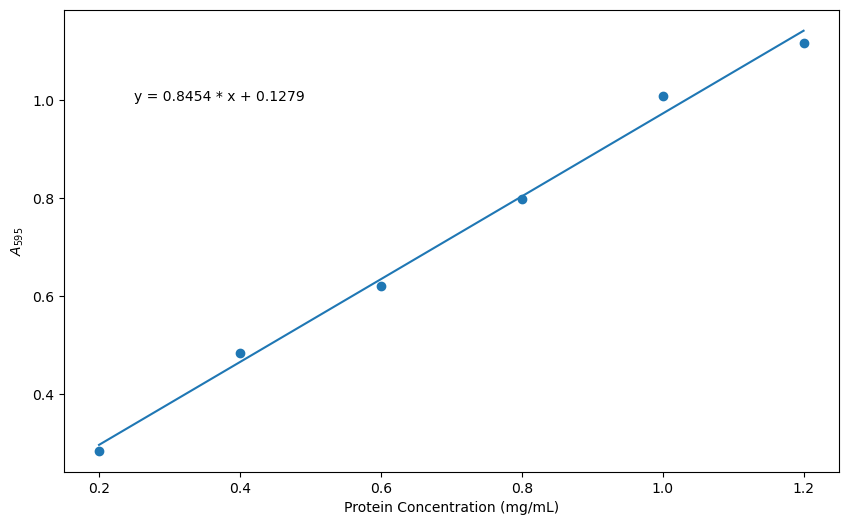
Check your Understanding
Take some time to play with the code for the figure above. Can you move the equation to the lower right hand corner of the plot?
Solution
You can simply change the xy pair in the last line of the code.
plt.annotate(F'y = {slope:.4f} * x + {intercept:.4f}', xy = (1.0, 0.4))
You may be asking yourself, “Why didn’t we generate a title for the figure?” That is certainly possible using the plt.title() function from matplotlib.pyplot. This was omitted because figures for publications and reports normally include separate text with a figure number, title and details as part of the text. To that end, we are going to learn to use the savefig command to produce a high resolution figure suitable for publication, which we will then learn to export to a file. Like many commands in python, it is simply a matter of getting the syntax right. We’ve added one line of code to save a high resolution image of our current figure.
plt.figure(figsize = (10,6))
plt.scatter(xdata, ydata)
plt.plot(xdata, slope * xdata + intercept)
plt.xlabel('Protein ($\mu$g)')
plt.ylabel('$A_{595}$')
plt.annotate(F'y = {slope:.4f} * x + {intercept:.4f}', xy = (0.25, 1.0))
plt.savefig('Bradford_plot.png', dpi = 600, bbox_inches = 'tight')
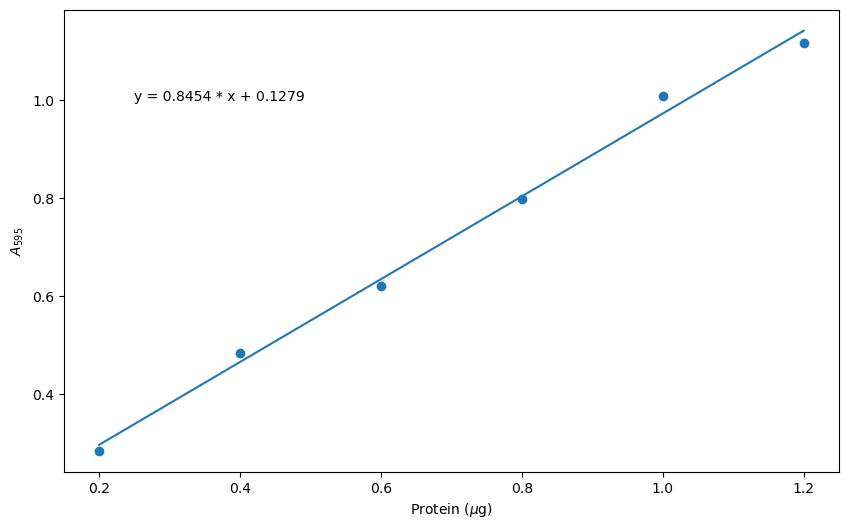
Let’s explore the line of code we wrote to save the figure. Once you have executed this command, you should find the plot in the same folder as the current Jupyter notebook.
plt.savefig('Bradford_plot.png', dpi = 600, bbox_inches = 'tight')
The arguments for plt.savefig are the filename (in single quotes because it is a string), the resolution (in dots per inch), the bounding box is ‘tight’, meaning that all the extra white space around the figure is removed.
There are many more options for plotting with matplotlib.pyplot. For example, if you wanted to have a red line in the plot, you could modify one line of code.
plt.plot(xdata, slope * xdata + intercept) # add the argument 'r-'
plt.plot(xdata, slope * xdata + intercept, 'r-') # red line
Scatter Plots with Seaborn#
Seaborn is a Python library for statistical data visualization that is based on matplotlib. That means you can use all the commands from Matplotlib with Seaborn, but it also has high-level functions that group many Matplotlib functions to produce sophisticated graphs easily.
Here we will use the Seaborn library to create a scatter plot that includes a confidence interval. Please note that Seaborn has dependencies on other libraries (numpy, scipy, pandas, and matplotlib), so these must be imported before you can use Seaborn.
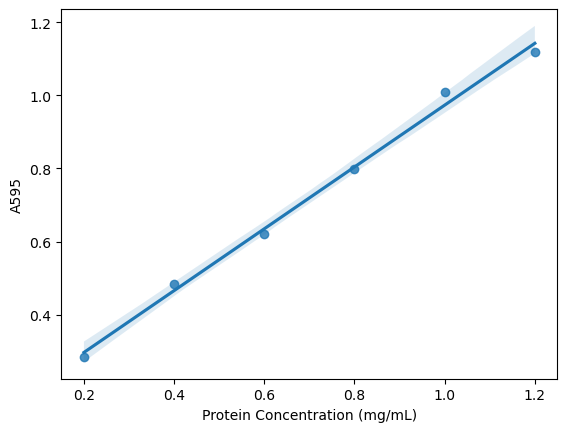
The following plot is based on resources at Statology. I prefer this plot to the simple linear regression above because it makes the reliable regions of the calibration curve more obvious by displaying the 95% confidence interval. It also emphasizes the valid range for calculations based on the plot - that we can’t use this curve to analyze absorbance values below 0.285 or above 1.118.
import os
import pandas as pd
protein_file = os.path.join('data', 'protein_assay.csv')
results_df = pd.read_csv(protein_file)
xdata = results_df['Protein Concentration (mg/mL)']
ydata = results_df['A595']
from scipy import stats
slope, intercept, r_value, p_value, std_err = stats.linregress(xdata, ydata)
import seaborn as sns
sns.regplot(x = xdata, y = ydata)
<Axes: xlabel='Protein Concentration (mg/mL)', ylabel='A595'>
Exercise
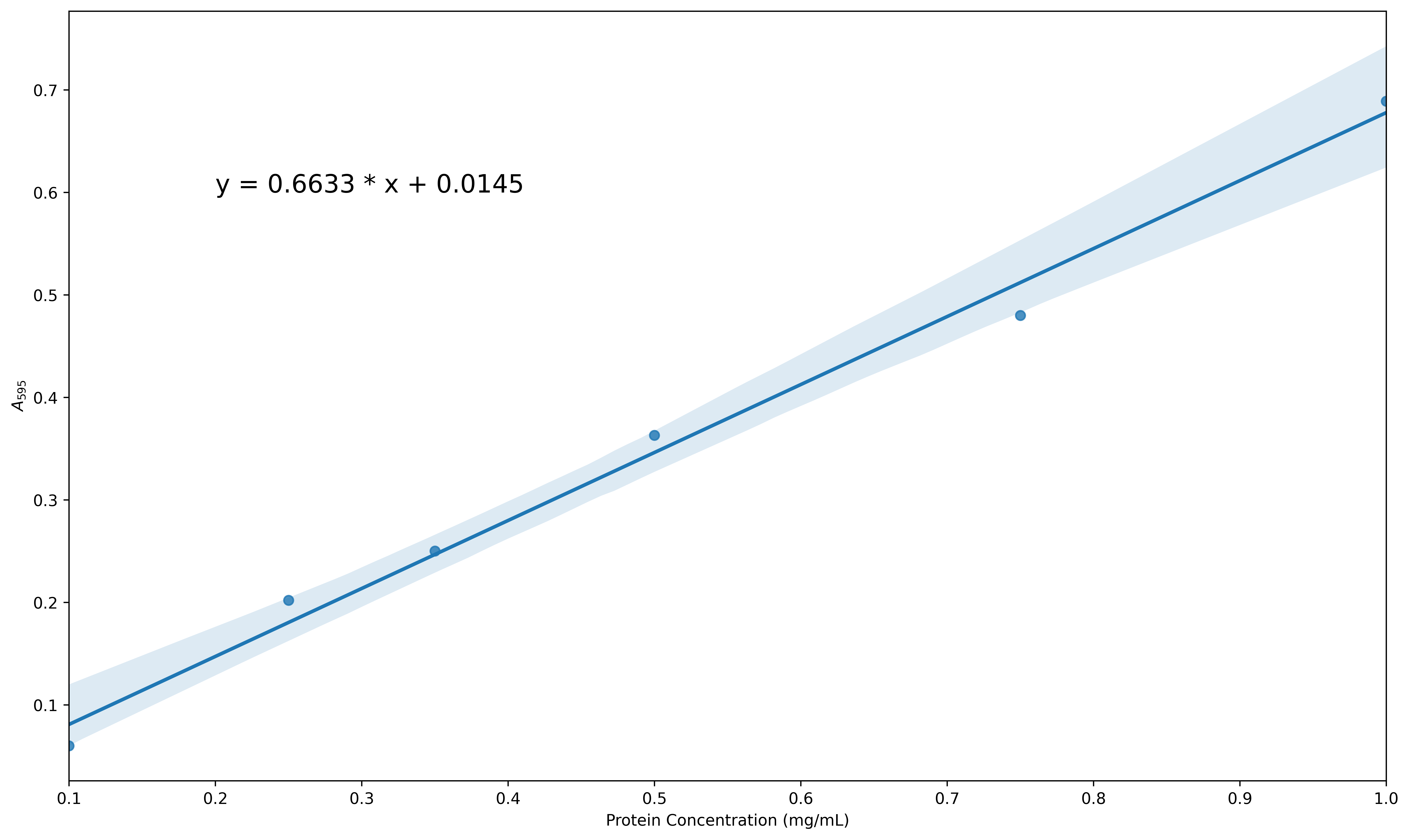
Use a similar approach to the one described above to create a linear regression plot with confidence intervals for data from a microplate assay that are a bit more scattered. The data can be found in the folder data/protein_assay2.csv. Increase the size of the figure, change the default x-axis and y-axis labels (taken by pandas from the column headers) to be Protein Concentration (mg/mL) and A\(_{595}\) as before and insert the equation for the line within the plot. You final figure should look something like this:
Solution
protein_file2 = os.path.join('data', 'protein_assay2.csv')
results_df = pd.read_csv(protein_file2)
xdata = results_df['mg/mL']
ydata = results_df['A595']
plt.figure(figsize = (15, 8))
from scipy import stats
slope, intercept, r_value, p_value, std_err = stats.linregress(xdata, ydata)
import seaborn as sns
sns.regplot(x = xdata, y = ydata)
plt.xlabel('Protein Concentration (mg/mL)')
plt.ylabel('$A_{595}$')
plt.annotate(F'y = {slope:.4f} * x + {intercept:.4f}', xy = (0.2, 0.5))
plt.savefig('Bradford_plot2.png', dpi = 600, bbox_inches = 'tight')
protein_file2 = os.path.join('data', 'protein_assay2.csv')
results_df = pd.read_csv(protein_file2)
xdata = results_df['mg/mL']
ydata = results_df['A595']
plt.figure(figsize = (15, 8))
from scipy import stats
slope, intercept, r_value, p_value, std_err = stats.linregress(xdata, ydata)
import seaborn as sns
sns.regplot(x = xdata, y = ydata)
plt.xlabel('Protein Concentration (mg/mL)')
plt.ylabel('$A_{595}$')
plt.annotate(F'y = {slope:.4f} * x + {intercept:.4f}', xy = (0.2, 0.5))
plt.savefig('Bradford_plot2.png', dpi = 600, bbox_inches = 'tight')
Key Points
Use the matplotlib library to prepare a plot with data and a best fit line.
Use the seaborn library to create a plot that includes a confidence interval.